Dernières Brèves
 Le plus haut observatoire du monde entre en fonction au Chili2 mai 2024Pour le Livre Guinness des records, l'Observatoire d'Atacama de l'Université de Tokyo (TAO) est l'observatoire astronomique le plus haut du monde. Le TAO se trouve à une altitude de 5 640 mètres au sommet d'une montagne dans le désert d'Atacama, au nord du Chili. Le télescope de 6,5 m optimisé pour les infrarouges est enfin opérationnel après 26 ans de planification et de construction......
Le plus haut observatoire du monde entre en fonction au Chili2 mai 2024Pour le Livre Guinness des records, l'Observatoire d'Atacama de l'Université de Tokyo (TAO) est l'observatoire astronomique le plus haut du monde. Le TAO se trouve à une altitude de 5 640 mètres au sommet d'une montagne dans le désert d'Atacama, au nord du Chili. Le télescope de 6,5 m optimisé pour les infrarouges est enfin opérationnel après 26 ans de planification et de construction...... La voile solaire avancée de la NASA s’est déployée sans encombre dans l’espace26 avril 2024La NASA a lancé son système de voile solaire composite avancé (Advanced Solar Sail) à bord d'une fusée Electron de RocketLab, déployant ainsi une voile de 9 mètres en orbite terrestre basse......
La voile solaire avancée de la NASA s’est déployée sans encombre dans l’espace26 avril 2024La NASA a lancé son système de voile solaire composite avancé (Advanced Solar Sail) à bord d'une fusée Electron de RocketLab, déployant ainsi une voile de 9 mètres en orbite terrestre basse...... Des millions de joueurs du jeu vidéo Borderlands 3 font avancer la recherche biomédicale24 avril 2024Plus de 4 millions de joueurs jouant à un mini-jeu de science citoyenne dans le jeu vidéo Borderlands 3 ont aidé à reconstituer l'histoire de l'évolution microbienne des bactéries de l'intestin humain......
Des millions de joueurs du jeu vidéo Borderlands 3 font avancer la recherche biomédicale24 avril 2024Plus de 4 millions de joueurs jouant à un mini-jeu de science citoyenne dans le jeu vidéo Borderlands 3 ont aidé à reconstituer l'histoire de l'évolution microbienne des bactéries de l'intestin humain...... La vieille sonde Voyager 1 de la NASA rétablit la transmission de ses données après 5 mois de charabia24 avril 2024La sonde Voyager 1 a renvoyé des données exploitables pour la première fois depuis plus de 5 mois, ce qui laisse espérer que la mission, vieille de 46 ans, pourra enfin reprendre ses activités normales. La sonde interstellaire préférée de la NASA a transmis samedi au centre de contrôle de la mission des données sur la santé et l'état de ses systèmes embarqués......
La vieille sonde Voyager 1 de la NASA rétablit la transmission de ses données après 5 mois de charabia24 avril 2024La sonde Voyager 1 a renvoyé des données exploitables pour la première fois depuis plus de 5 mois, ce qui laisse espérer que la mission, vieille de 46 ans, pourra enfin reprendre ses activités normales. La sonde interstellaire préférée de la NASA a transmis samedi au centre de contrôle de la mission des données sur la santé et l'état de ses systèmes embarqués......
Une intelligence artificielle donne vie à la Joconde et à d’autres portraits

Utilisant la dernière tendance dans le domaine de l’intelligence artificielle (IA), appelée apprentissage machine antagoniste (Adversarial machine learning), le Centre d’IA de Samsung à Moscou a démontré qu’il peut utiliser une seule image d’une personne et la mettre en mouvement.
Le système utilise un certain nombre d’images d’une personne, de une à plusieurs afin d’obtenir de meilleurs résultats, et les faits passer dans un » traceur/ suiveur de repère du visage » prêt à l’emploi pour déterminer où se trouvent les yeux, les sourcils, le nez, les lèvres et la mâchoire. Il en va de même pour une autre vidéo source « pilote », en image par image pour suivre le mouvement de ces repères faciaux.
Il y a une étape distincte d’apprentissage, au cours de laquelle différents réseaux d’IA sont formés pour effectuer différentes tâches, en utilisant un énorme ensemble de données vidéo de têtes parlantes. Un réseau “Embedder” prend les trames sources et leurs données de suivi des points de repère pour créer des vecteurs, tandis qu’un réseau “Generator” (génératif) apprend à récupérer les vecteurs et les images pour générer de courtes vidéos dans lesquelles les visages fixes sont animés pour bouger selon le mouvement du vecteur.
Le troisième réseau « Discriminator » met en place la relation “contradictoire/ concurrentielle”, il apprend à regarder des vidéos de visages en mouvement, et à faire la différence entre les vraies vidéos, de celles qui ont été truquées par le réseau Generator. Il y a donc deux réseaux qui s’opposent l’un à l’autre, l’un essayant de tromper l’autre, l’autre de repérer les faux.
Ces réseaux débutent assez mal leur travail, mais comme ils l’exécutent des millions de fois, ils s’améliorent au fil du temps, et la concurrence entre les deux réseaux est ce qui les pousse à s’améliorer. Le réseau Discriminator ne cherche pas les mêmes choses qu’un faux observateur humain, mais cela n’a pas d’importance, quoiqu’il cherche, il s’améliore sans cesse dans la discrimination, donc le réseau Generator doit continuer à s’améliorer pour continuer à le tromper.
C’est un autre aperçu du potentiel très intéressant des réseaux antagonistes génératifs, qui font leur apparition dans le monde des IA. Mais pour vraiment l’apprécier, il faudra regarder la vidéo ci-dessous.
Passez directement à 4mn 16 secs si vous voulez voir comment le modèle se comporte avec les photos de Marilyn Monroe, Salvador Dali, Raspoutine et Einstein, puis avec des peintures.
De voir la Joconde prendre vie pourrait faire sourire, jusqu’à prendre conscience que de tels développements signifient plus de réalisme et de facilité à produire des Deepfakes (permutation intelligente de visages).
L’étude en prépublication sur arXiv (PDF) : Few-Shot Adversarial Learning of Realistic Neural Talking Head Models.
[totaldonations_circle_bar id="81539"]
Il n'y a pas de publicité ici et le Guru tente, cette semaine, de réunir les fonds nécessaires pour continuer à faire vivre GuruMeditation. On y est presque et votre aide est absolument nécessaire et cela se passe ici.
Derniers Articles
 Le Guru fait une pause dans ses écrits, car il a besoin de votre soutien !7 mai 2024Le Guru lance un appel aux dons afin de l’aider à poursuivre son activité…...
Le Guru fait une pause dans ses écrits, car il a besoin de votre soutien !7 mai 2024Le Guru lance un appel aux dons afin de l’aider à poursuivre son activité…... Un orang-outan est le premier non-humain à soigner des blessures à l’aide d’une plante médicinale4 mai 2024]Un orang-outan sauvage mâle de Sumatra a été observé en train d'appliquer les feuilles mâchées d'une plante aux propriétés médicinales connues sur une plaie de sa joue. Il s'agirait du premier cas documenté de traitement actif d'une plaie par un animal sauvage à l'aide d'une substance végétale biologiquement active connue. Les chercheurs ont observé l'orang-outan, qu'ils ont baptisé Rakus, en juin 2022 dans la zone de recherche de Suaq Balimbing, dans le parc national de......
Un orang-outan est le premier non-humain à soigner des blessures à l’aide d’une plante médicinale4 mai 2024]Un orang-outan sauvage mâle de Sumatra a été observé en train d'appliquer les feuilles mâchées d'une plante aux propriétés médicinales connues sur une plaie de sa joue. Il s'agirait du premier cas documenté de traitement actif d'une plaie par un animal sauvage à l'aide d'une substance végétale biologiquement active connue. Les chercheurs ont observé l'orang-outan, qu'ils ont baptisé Rakus, en juin 2022 dans la zone de recherche de Suaq Balimbing, dans le parc national de...... Des chercheurs reconstituent le visage d’une Néandertalienne à partir d’un crâne écrasé vieux de 75 000 ans4 mai 2024Une équipe de paléo-archéologues est présentée dans un nouveau documentaire dans lequel ces experts ont reconstitué le visage d'une femme néandertalienne ayant vécu il y a 75 000 ans. Le crâne, écrasé en centaines de fragments probablement par un éboulement après la mort, a été déterré en 2018 dans la grotte de Shanidar, au Kurdistan irakien. Baptisés Shanidar Z, les restes du Néandertalien sont peut-être la partie supérieure d'un squelette découvert dans......
Des chercheurs reconstituent le visage d’une Néandertalienne à partir d’un crâne écrasé vieux de 75 000 ans4 mai 2024Une équipe de paléo-archéologues est présentée dans un nouveau documentaire dans lequel ces experts ont reconstitué le visage d'une femme néandertalienne ayant vécu il y a 75 000 ans. Le crâne, écrasé en centaines de fragments probablement par un éboulement après la mort, a été déterré en 2018 dans la grotte de Shanidar, au Kurdistan irakien. Baptisés Shanidar Z, les restes du Néandertalien sont peut-être la partie supérieure d'un squelette découvert dans......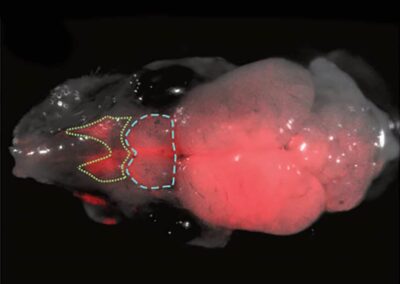 Des scientifiques créent des cerveaux hybrides souris-rat avec des neurones des deux espèces4 mai 2024Des chercheurs américains ont utilisé une technique spéciale pour éliminer les neurones de souris en développement, qu'ils ont remplacés par des cellules souches de rat. Ces cellules se sont transformées en neurones de rat dans le cerveau de la souris, qui est AINSI devenu un cerveau hybride. Chose remarquable, les rongeurs modifiés sont en bonne santé et se comportent normalement, ce qui est très prometteur pour les thérapies régénératives neuronales. Les recherches ont été menées par deux équipes indépendantes, qui ont publié leurs résultats......
Des scientifiques créent des cerveaux hybrides souris-rat avec des neurones des deux espèces4 mai 2024Des chercheurs américains ont utilisé une technique spéciale pour éliminer les neurones de souris en développement, qu'ils ont remplacés par des cellules souches de rat. Ces cellules se sont transformées en neurones de rat dans le cerveau de la souris, qui est AINSI devenu un cerveau hybride. Chose remarquable, les rongeurs modifiés sont en bonne santé et se comportent normalement, ce qui est très prometteur pour les thérapies régénératives neuronales. Les recherches ont été menées par deux équipes indépendantes, qui ont publié leurs résultats......
Pas Raspoutine: Dostoievski